Craig Rowe
6 min read • 21 February 2019
API’s have gone mainstream. Gone are the days of walled garden black box systems. Almost every service you use online now probably also exposes an API for developers to build on and add to their ecosystem. The success of many private sector organisations has been driven by the ability of third-party developers to plug in and add to their offering in ways that they have not imagined or for niches they could not yet focus on.
We’re also starting to see this trend emerge in the public sector. Since the Freedom of Information Act, there has been a move towards more civilian access to both the data that the government holds on you and the data that the government has funded with your taxes.
Even as a business owner without altruistic views on the freedom of data, servicing customers on multiple platforms (Phones, Watches, Televisions, Cars) means you will almost certainly need some form of API for those individual devices to connect into to provide value and strong seamless experiences to your customers.
The progression
As the likelihood of needing an API has increased, their requirements have evolved in kind. If you are a going to expose data to a worldwide audience you cannot be complacent when thinking about performance and cost. However by adding swathes of non-functional requirements (NFRs), you’re also adding complexity to the implementation, and that complexity can mean increased development cost and increased risk of errors and bugs.
Fortunately for us alongside the growth of APIs has been the growth of Cloud service providers.
These providers, such as Microsoft with their Azure platform, have been investing in their platforms and building more and more into their offerings to address commonalities, helping us avoid reinvention of the wheel and make the development of a new service or application cheaper and safer overall.
Much of this comes under the umbrella term of Platform as a Service (PaaS) where many or all of the infrastructure concerns of the past are hidden from you, as the developer of a cloud service.
Standing on the shoulders of giants
So let's quickly enumerate the sorts of features we may be talking about:
- Near instant worldwide response
- Rate limits to avoid misuse
- Quota limits to allow for tiered access
- Secured access
- Load testing to prove the robustness
- Multiple environments for varying levels of QA with fast and reliable migrations
- A developer portal for your clients to gain access
Going back a few years, we remember when delivering an API with these requirements would mean a large development and ops team orchestrating load balancers, multiple servers implementing the API and its complimentary web pages.
However, the evolution of cloud computing means we can approach things a little differently…
We wanted to share our experience from a recent public sector client project which needed all of the NFRs above, whilst exposing a read-only view of a very large dataset (3 million + records).
A codeless solution
It is now possible to develop many of the above NFRs with no code, only configuration. In fact, depending on the API requirements you may need little to no code at all - even for the API piece itself. This was the case with our public sector client. To add another layer of complexity to the mix, we were tasked with completing the project in under a month. So to deliver our performant APIs on very short timescales we looked to Microsoft Azure.
Azure API Management (APIM)
The majority of Azure features are exposed to developers as ‘resources’ that can be provisioned using the Azure Portal web interface or in an automated fashion with Azure Resource Manager (ARM) templates. This means there is no installation or remote desktopping/shell access to configure - leading to fewer mistakes and opening up the ability to configure complex infrastructure to the masses.
One such Azure resource that can help considerably with developing and publishing a web API is ‘API Management’. API Management, among many features, acts as a proxy for an underlying API and as with most Azure Resources, it is billed at tiered levels. Basic and standard tiers can include multiple instances while premium allows specific geo-location settings for redundancy. This is all handled transparently - so there’s no configuring of load balancers or managing multiple physical machines. Scaling up and down can be undertaken in a matter of minutes.
One API Management instance can manage multiple apis (made distinct by their root path). The definition of these APIs is best made by creating an OpenAPI specification document and uploading it through the Web Portal.
Once APIs have been created they can have certain configurations associated with them, known as an APIM Policy. These policy documents are written in XML but can include code. If we look at two simple examples we can see how truly powerful these policies can be:

The above is the simplest example of configuring rate limiting. With just the above added to a policy individual subscribers to the API will be limited to 100 requests within a minute period. If users of the API breach this limit they will receive responses with the http error status code 429.

The companion to the rate limit is the quota i.e. the total amount over a large period that is permitted as opposed to the peak frequency limitation of a rate limit. This is similarly simple to configure for all subscribers with the above Policy xml.
Both policies can be far more detailed, for example, you can configure your own ‘key’ for deciding how you identify users for the purpose of using up their limits. Policies can be applied at the entire API level, at the individual operation levels or at the ‘product’ level (a parent level above APIs).
In addition to this ‘configuration’ approach to infrastructure operations, APIM provides a skinnable developer portal that allows your users to sign up and request subscription key access to the underlying APIs.
But what are we proxying to?
The above features drastically thin out the effort required to do many of the NFR’s mentioned earlier but we haven’t yet touched on how we actually make the API that sits behind APIM. Traditionally this would be some kind of bespoke coded application, most likely with some persistent data sitting behind it.
However, in a cloud and PaaS world, we can do things a little differently…
Intelligent Persistence Layers
At the same time as cloud providers were appearing NoSQL databases were growing with the likes of MongoDB being released at similar times to Azure itself. In a NoSQL world, we can store ‘documents’ in a persistence layer rather than worrying about exact schemas, normalisation and joins. In addition to that, many NoSQL providers allow for access to the data via a REST API - CouchDB and Microsoft’s own CosmosDB are two examples.
If our persistence layer is accessible over HTTP then our APIM instance can proxy directly to it rather than requiring code in the middle. This isn’t necessarily adequate for all use cases but remember, many of the reasons we may need code in the middle have now been removed - with APIM policies and configuration potentially able to cover security, filtering, rate limiting, data transformations etc.
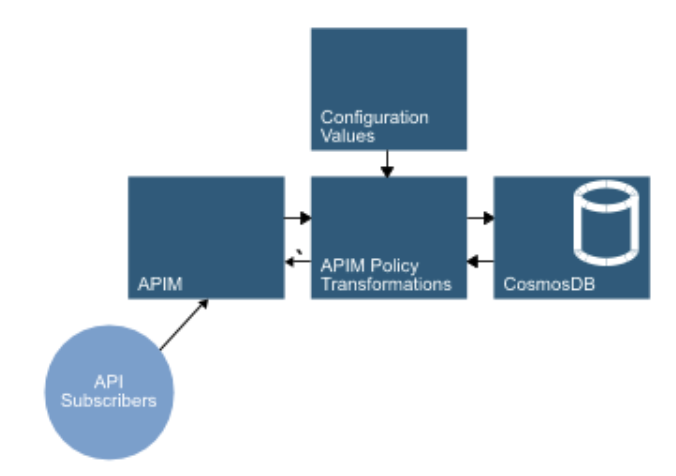
An added benefit of this approach is that CosmosDB can be considerably cheaper than running a more traditional database.
A simple example
Let’s think about a simple ‘get entity’ endpoint. With CosmosDB the URL to access a document takes the form:
dbs/[Database]/colls/[CollectionName]/docs/[documentKey]
An Operation (single API URL) in an APIM configuration will have a base Web Service URL set. APIM will then append any path from the external request URL to the end of the base URL. Though this can be easily modified with a rewrite-uri element.

An APIM policy attached to an API operation can forward on the request filling in the appropriate values either via a parameter or baked in configuration. In the above example, we pull a documentKey value from the inbound parameters and append it to the collectionName/docs part of the Cosmos query.
The only complexity with CosmosDB then is the generation of an appropriate authorization header. Fortunately, APIM Policies can contain C# (though its use should be minimal) so the header can be generated using configuration values for keys without the need for a separate application service or function between APIM and Cosmos.
In this scenario, we are now entirely relying upon Azure resources with on-demand scaling and tight integration to Azure analytics. We run no requests through Virtual Machines or PaaS application services and yet we can set rate limits, transform data and manipulate responses all from configuration.
The capacity to handle load is now limited only by Azure itself rather than our own code. Our recent project was able to handle close to 7,000 requests a second when APIM caching was enabled.
Monitoring
Basic logging is provided by APIM but this can be augmented by attaching to an Application Insights resource in Azure. This configuration can include the entirety of every request or be setup to log a percentage sampling.
Application insights is a story for another day but it is a very powerful tool that allows multiple ways to break down your data as well as automate alert triggers for important thresholds.
Integrated Automation

To round out the development story let’s look at how we would create these resources in the cloud. The above is a snippet of an ARM template. All templates are written in a similar JSON structure. We can see how the activation of a specifically geo-located API proxy with predefined capacity can be created without laborious, error-prone steps. In addition, these files are eminently source controllable allowing full tracking of the changes to your infrastructure.
With infrastructure being treated as code in this way Azure DevOps build/release pipelines can be used to set up and tear down as many dev/test/stage environments as necessary at the click of a button.
So, ready to begin?
Although it may not be applicable for very logic heavy APIs as developers we now need to look carefully at all deployment options. Falling back to a Virtual Machine and Relational Database is not always the most optimal approach for performance and even if it were the benefits of PaaS and Infrastructure as code can greatly reduce your Operations overhead.
By utilising these tools we were able to create, load test and deploy an API in a matter of weeks whereas in the past this could have taken months.
Want to understand how Infrastructure as code could benefit your organisation? Ask us now!
Craig Rowe


